
The Frontier Moves Again
AI progress above and below the surface.

Stacks of documents dissolving into flowing streams of symbols, then assembling into a single glowing decision-tree
Progress: AGI In Plain Sight
This blog was half-written when Gemini 3 was released – a summary of progress since my last AI report on the frontier in late August. I have had to refocus it.
It is clear Gemini 3 is well in front of its rivals, achieving stunning (and if you’ve been reading previous blogs – alarming) progress.
Many of the claims in the first 24hrs will overshoot, and be corrected. More will be made, and upheld in the coming days. But at first glance, it looks like another big jump forward towards AGI.
Sundar Pichai, Google CEO, says it is the ‘best model in the world for multimodal understanding, and our most powerful agentic + vibe coding model yet. Gemini 3 can bring any idea to life, quickly grasping context and intent so you can get what you need with less prompting“.
Here are few claims that are well established.
Gemini 3 has made a huge jump to scoring 31% on the Advanced Reasoning Corpus (ARC) AGI 2 benchmark. I remind you again that ARC AGI 1 was set up to show LLMs couldn’t reason, and that should models meet the benchmark, it would be an indication they were a general intelligence.
After big progress was made on ARC AGI 1 in late December last year, ARC AGI 2 was rolled out. This was when I wrote ‘Eyes Wide Shut: AGI in Plain Sight ‘ here on the blog. 11-months ago.
Here’s Gemini 3 on ARC AGI 1, at 87%...

And here it is on the new harder AGI test. Errr…

Gemini 3 is now scoring 31% on this test when given to the model alone. Let the model use tools and search the web, it gets 45%.
The team behind ARC AGI 1 and 2 are now launching ARC AGI 3, and while this will be genuinely testing intelligence in new ways, is useful, welcome and needed - if you can’t see the way we keep moving the goalposts I don’t know what more to say.
Remember Humanity’s Last Exam? Take a look at the left hand side of the Evals chart Google released on their blog:
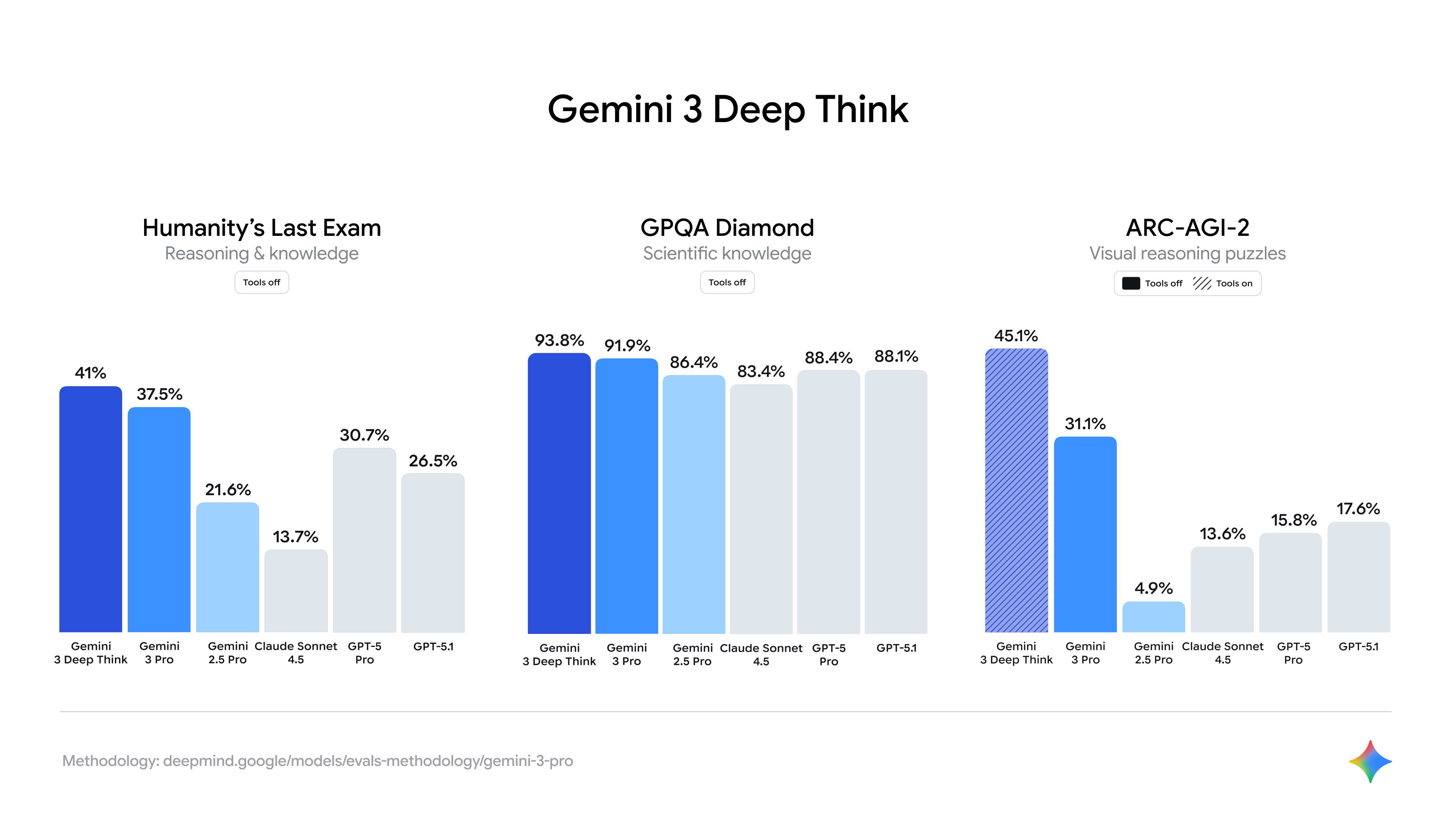
Humanity’s Last Exam haven’t updated their leaderboard yet, but Grok 4 was previously winning with 25%. Gemini 3 is at 41%.
Concurrently, Google released Antigravity, which it says is “an agentic development platform, evolving the Integrated Development Environment into the agent-first era”. In other words, its an environment that can further automate software engineering using Agents.
It’s getting rave reviews for what it can do – I tested it last night and in one-shot, it produced an app we were developing with an external team. I haven’t validated or verified it yet, but it looks good and seems to work. The point is not that it will be better than what the team we are paying will produce – I don’t think it will be. But it will be close, it raises the bar, and it shows, I think, the direction of travel – AI eating software, where you prompt AI to build you the tools and apps you want and need, bespoke.
And if you’re reading this sat in a large organisation, here’s something else to pay attention to: evaluation site Box tested Gemini 3 vs ‘advanced reasoning tasks on enterprise documents, Gemini 3 Pro saw a 22% gain in performance on complex data analysis across a wide range of industries.’ Here’s the high-level results:

The progress is broken out in the industries where it was most notable. The authors at Box write:
In Healthcare & Life Sciences, Gemini 3 Pro achieved 94% accuracy, compared to just 45% for Gemini 2.5 Pro.
In Media & Entertainment, Gemini 3 Pro reached 92% accuracy, a massive increase from 47% for the previous model.
In Financial Services, Gemini 3 Pro saw 60% accuracy, up from 51% for Gemini 2.5 Pro.
The CEO of Box, Aaron Levi described the kind of thing they did:
“For this test, we ask the model a series of complex, real-world questions with a set of enterprise documents. The questions are meant to approximate what a person does in their daily work across various fields of knowledge work. This may include what an investor would do to analyze the financial health of a company, or what a consultant would do to build a report for a client on a complicated strategic topic.
Gemini 3 Pro represents a major leap in reasoning, math, logic, and analytical capabilities.
These gains show up as delivering highly useful improvements across financial services, law, healthcare, public sector, manufacturing, and more.”
Can you see where we are going yet?
I’m sticking to Gemini 3 here, but I don’t believe GPT-5 was evidence AI was ‘hitting a wall’ as many have suggested – its scores on most evals were good e.g. take a look at SimpleBench, which summaries multiple benchmark leaderboards, and you’ll find GPT-5 only exceeded on most benchmarks by Gemini 3 on its release yesterday. GPT-5 is always there or thereabout at the top, and on quite a few still on top even post Gemini 3 launch, with some remarkable scores. My day to day use of GPT-5’s advance reasoning and research constantly amazes me. I just think people have adjusted to how remarkable AI has become, and that most aren’t routinely using the latest models, so ChatGPT was unjustifiably felt to have not lived up to the hype. But that is probably a different blog post, and it hardly feels worth detaining us with this evening – remembering that at Gemini 3’s release we are just two and half months after GPT-5’s debut. Even if you believed GPT-5 suggested a slow down in LLM progress, presumably you’d accept Gemini 3 is evidence the field has some way to go yet.
Grok 4 and Claude Sonnet 3.5 have also achieved remarkable further progress since I last wrote a more general AI update in late August, and again it won’t be possible to do this full justice here.
One remarkable development that we must draw attention to - here’s Logan Graham, who leads the Red Team at Anthropic, reporting on Anthropic’s post, that describes their identifying a first AI-led espionage campaign, where 80-90% of the cyberattacks were undertaken by Claude’s Agentic AI, most likely being used by China. Logan, who is better placed than most to understand where the frontier is and how fast it is moving, wrote “My prediction from ~summer ‘25 was that we’d see this in ≤12 months. It took 3.” As we’ve noted before - we are still underestimating the rate and profundity of AI progress.
There have been scientific breakthroughs and much more since August, perhaps to be summarised in a future post, but here, having given sense of how fast we are observing the very visible process in LLMs, I want to look a little deeper, to what is less obvious - but important all the same.
Progress: Beneath the Surface
Just a few days ago, Deepmind released SIMA 2, which Demis Hassabis, normally known for being more conservative than many industry leaders described as:
“a general agent that can understand & reason about complex instructions and complete tasks in simulated game worlds, even ones it has never seen before. Incredible to see how it can learn just from self-play… a crucial step towards AGI.”
His cofounder Shane Legg was similarly exuberant celebrating how “3 years ago I started the SIMA project with the dream of using 3D games as worlds in which to train and test Gemini based game agents — all as a stepping stone towards real world AGI.”
SIMA 2 can be dropped into novel games and teach itself new skills, learn through trial-and-error, and get better the more it plays, without any human input.
What it is doing is reasoning but not in the abstract question and answer sense that Gemini usually does, but rather as an embodied avatar in a virtual world – it can describe what it ‘sees’, take instructions and reason its way in the pursuit of a goal. Not so much something you command as something you plot with, as if there were two of you on a mission figuring out how to succeed. It can also transfer learning from one environment, or game, to another.
Deepmind also applied SIMA 2 within Genie 3 – its model that let you generate new, persistent, real-time 3D worlds from a single image or text prompt. In these wholly novel environment SIMA 2 still succeeds – interacting with you as you explore and investigate.
As Deepmind describe, that it can learn in all these environments without human input ‘paves the way for a future where agents can learn and grow with minimal human intervention, becoming open-ended learners in embodied AI’.
In other words, it takes us towards a world in which AI in robotics can learn without human input, solve long time horizon tasks, learn new skills and apply them across domains.
While there are still limitations in this new paradigm – very long time horizon reasoning and some particularly complex tasks remain beyond it – the capabilities are remarkable. That they have elicited barely a mention in the press is indicative of a continued failure to appreciate the rate and direction of progress, and the profundity of its implications.
Oh – did I mention Genie 3? This is another model released since I last wrote about AI progress. Genie 3 can be summarised as providing limitless interactive environments from text prompts. Maybe read that again.
Google also released Earth AI with a Geospatial Reasoning Agent. They show how this can be used to direct aid to where it is most needed in the event of a natural disaster – predicting the disaster’s effects and assigning resources accordingly. But it shows how similar models – Digital Twins + Reasoning Agents could equally be used in the military domain to understand the likely effects of an attack, how Governments could use such models for resilience planning, how businesses will likely be tracking supply chain security, how all sorts of organisations can and will predict the effects of events or interventions of many kinds, in many domains.
A new paper this week builds on Deepmind’s release last year in May 2025 (keeping the error visible – I think it shows how AI progress is so rapid it can distort your sense of time!) of AlphaEvolve, which constantly evolves new algorithms (variation and selection) and had previously helped improve ‘Google’s data centers, chip design and AI training processes — including training the large language models underlying AlphaEvolve itself’. The new paper shows how the approach of ‘breeding’ algorithms can succeed in solving maths problems, autonomously discovering novel mathematical constructions and improving best-known bounds across dozens of open problems, not just optimise algorithms - showing this across 67 problems in analysis, combinatorics, geometry and number theory.
This approach of continuously ‘evolving’ new algorithms vs particular problems is another one of several that suggest possible paths to AGI beyond the current, dominant, LLM architectures.
SIMA 2, Genie 3 and AlphaEvolve probably won’t make much difference to what you are doing at work tomorrow or in the next few months – whereas Gemini 3 might. But their significance lies in what they augur.
AI luminary (previously Director of AI at Tesla) Andrej Karpathy wrote back in August that we are entering ‘the age of environments’ – so where access to text for training AI was once the key requirement, increasingly, as we build AI optimised for the real world, access to simulated environments will matter more. Genie 3’s limitless interactive environments from text prompts – is an example of what Karpathy was talking about. SIMA-2’s performance within it, shows how quickly progress is being made. AlphaEvolve shows how many tasks will be solved not by static models, but by continuously evolving intelligent solutions. All suggest that even if LLMs were ‘hitting a wall’, which I don’t believe is the case yet, there are many approaches to smash through it and keep those straight lines on graphs heading upward and to the right.
There are plenty of other remarkable developments in the past few months. To summarise just a few:
· Deepseek’s Optical Character Recognition model, compresses text into a visual format before decoding it, cutting token usage by seven- to twenty-fold while preserving accuracy - showing how vision-based encoding could ease today’s long-context bottlenecks, take in a lot more text, and produce a lot more text, more accurately.
· Meta’s AI/VR Glasses, which some claim might replace the need for smartphones and smartwatches, and open the way to generative user interfaces i.e. creating the dashboards and tools you need in the air in front of you.
· For self-driving sceptics, reading Andrej Karpathy’s recent post should be a corrective, showing just how far Tesla has come and how few (technological) barriers remain to the widespread deployment of self-driving systems – and it is worth noting how these pave the way for much more effective robotic systems in general, not just self-driving cars.
· Emerging evidence that video models may be on a trajectory towards general-purpose vision understanding, much like LLMs developed general-purpose language understanding – that video models, not trained to reason, are showing the capacity to do so. Here’s OpenAI’s Bill Peeble, Head of Sora, OpenAI’s video models, claiming video models are on the critical path to AGI.
But the point is not to over-emphasise these developments, but to show how many parallel paths to AGI are being pursued, even as the main path continues to take us ever closer to that milestone, and as we have often discussed: closer to the most disruptive revolution in human history.
Visit us www.cassi-ai.com
Great post, Keith! Barely treading water when it comes to keeping pace with the latest developments, so this was a super useful summary. Hope all is well!
Fascinating. You prompted me to get into a nuanced conversation with ChatGPT (not Pro) about the prospects for architectural convergence of the various discrete approaches towards AGI you describe. It concluded with a prediction that there are clear signs of convergence, and gave me the following formulation: AGI = LLM + Agency + Environments + Tools + Self-Improvement Loops. Is there any consensus on this amongst human commentators such as yourself?